回到上一章
事务的引入
- 计算环境的脆弱性—故障恢复问题
- 银行转帐(故障恢复)
- 计算环境的分布性—并发控制问题
- 订飞机票(并发执行)
事务示例
银行转帐:事务T从A帐户过户50¥到B帐户1
2
3
4
5
6T:read(A);
A := A – 50;
write(A);
read(B);
B := B + 50;
write(B);
其中
1 | read(X):从数据库传送数据项X到事务的工作区中 |
事务中数据访问过程
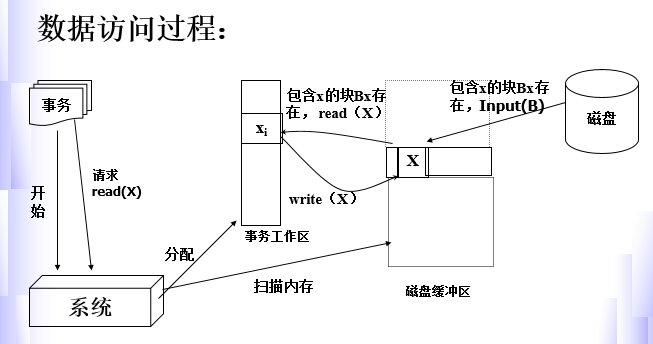
可恢复操作的问题与模型
故障模式:
- 错误数据输入:引入约束机制
- 但有些错误是无法检测的,例如输错某一位。
- 介质故障
- 磁盘局部故障:可通过奇偶校验检测
- 磁盘重大故障:利用RAID
- 灾难性故障
- RAID失效,因系统中所有磁盘均被破坏
- 可用备份或冗余分布式拷贝恢复
- 系统故障:是导致事务状态丢失的问题
- 掉电或软件错误
- 无法确定事务的哪些部分(包括对数据库的修改)已经进行
事务:
- 事务是数据库操作的执行单位。每一个查询或数据库更新语句就是—个事务
- 在嵌入式SQL系统中,一旦对数据库进行的操作执行,事务就开始,而事务的结束使用显式的commit或rollback结束
- SQL中事务的定义
- 事务以Begin transaction开始,以Commit work或 Rollback work结束
- Commit work表示提交,事务正常结束
- Rollback work表示事务非正常结束,撤消事务已做的操作,回滚到事务开始时的状态
事务的ACID特性
A:表示事务的原子性(Atomicity),即事务完全执行或完全不执行
- 事务中包含的所有操作要么全做,要么全不做原子性由恢复机制实现
C:表示一致性(Consistency),所有数据库都有一致性约束,或关于数据之间联系的预期状态
- 事务的隔离执行必须保证数据库的一致性。事务开始前,数据库处于一致性的状态;事务结束后,数据库必须仍处于一致性状态。
- 数据库的一致性状态由用户来负责,由并发控制机制实现。如银行转帐,转帐前后两个帐户金额之和应保持不变
I:表示隔离(Isolation),即表面看起来,每个事务都是在没有其它事务同时执行的情况下执行的
- 系统必须保证事务不受其它并发执行事务的影响。对任何一对事务T1,T2,在T1看来,T2要么在T1开始之前已经结束,要么在T1完成之后再开始执行
- 隔离性通过并发控制机制实现
D:表示持久性(Durability),即一旦事务完成了, 事务对数据库的影响就不会丢失
- 一个事务一旦提交之后,它对数据库的影响必须是永久的
- 系统发生故障不能改变事务的持久性。持久性通过恢复机制实现
事务
事务与数据库交互过程中使用的三种地址空间
- 保存数据库元素的磁盘块空间
- 缓冲区管理器管理的地址空间
- 事务的局部地址空间
三种空间的计划过程如下图所示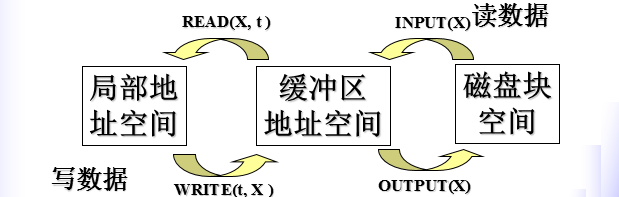
上图中1
2READ(X, t)和WRITE(t, X)由事务发出
INPUT(X)和OUTPUT(X)由缓冲区管理器发出
事务的原语操作
用一种记法来描述使数据在地址空间之间移动的操作:
- 1.INPUT(X):将包含数据库元素X的磁盘块拷贝到主存缓冲区
- 2.READ(X, t):将数据库元素X拷贝到事务的局部变量t
- 3.WRITE(X, t):将局部变量t的值拷贝到主存缓冲区中的数据库元素X
- OUTPUT(X):将包含X的缓冲区拷贝回磁盘
事务状态
下图说明了事务的几种状态以及这些状态间的转换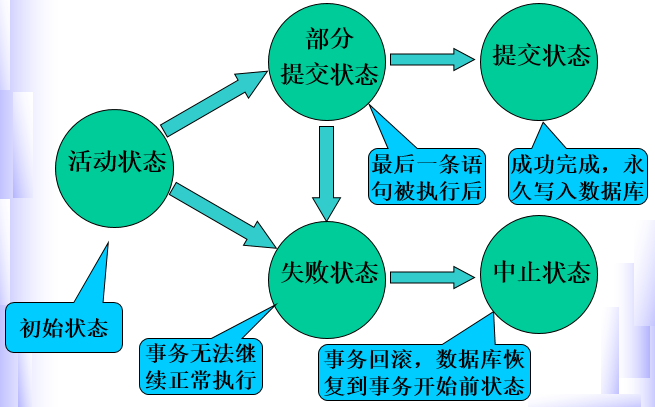
undo 日志
- 日志
- 日志是日志记录的一个序列,用于记载有关某个事务已做的事的某些情况
- 日志块最初在主存中创建,一旦合适,日志块就被永久地写到磁盘上
- 日志记录的格式
,表示事务T已经开始 ,表示事务T成功完成 ,事务T未成功,被中止
- 更新记录
- undo日志规则
使用undo日志的恢复
- 如果不能完全确定事务的影响已经完成并且已经存储到磁盘上,那么事务对数据库所做的所有更新都将被撤销,数据库被恢复,就好像这 - 些事务从来未曾执行过。
更新记录
- 注意: undo日志不记录数据库元素的新值,而只记录旧值。如果在使用undo日志的系统中需要进行恢复时,恢复管理器要做的唯一事情是 通过恢复旧值消除事务可能在磁盘上造成的影响
- undo日志的规则
对于任一事务T,按照如下顺序向磁盘输出
T的日志信息:- 首先,写更新日志记录
- 其次,改变数据库,执行OUTPUT(X)
- 最后,写
日志
但是顺序是对各个数据库元素单独适用,而不是对事务的更新记录集合整个适用
→立即修改的技术
允许数据库修改在事务仍处于活跃状态时就输出到数据库中,此时称其为未提交修改
- 首先,写更新日志记录
例如对于下面的事务![]()
其对应的日志顺序为![]()
使用undo日志进行恢复
- 从尾部开始扫描日志
- 在扫描过程中,记住所有有
和 记录的事务T - 在由尾部向后扫描的过程中,若看到
有记录- 若T的COMMIT记录已经被扫描到,则什么也不做;
- 否则,T是一个未完成的事务或被中止的事务。必须将数据库中X的值改为v。然后,将
写入磁盘
例如对于下面的事务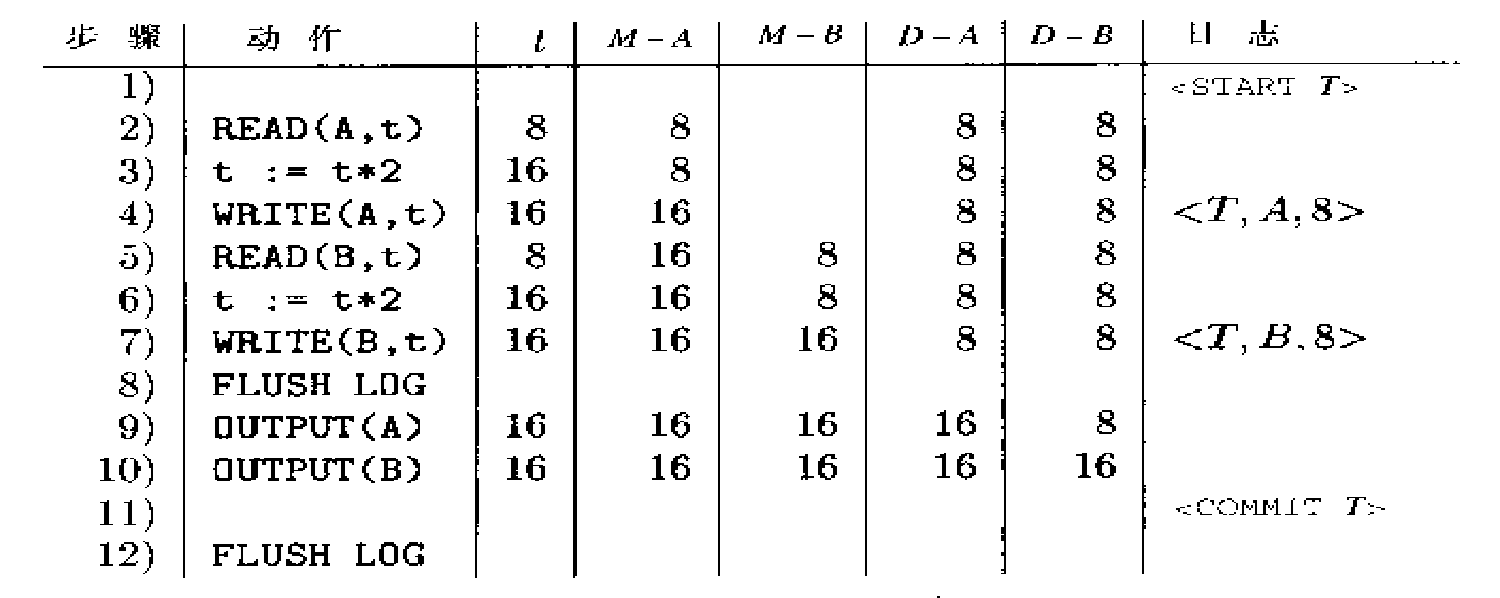
- 若执行到第2~11步中的任意一步发生故障,
- 利用undo日志,恢复旧值
- 若执行完第12步后发生故障,则表示T已经完全执行完,不必做任何处理动作
检查点:周期性地对日志作检查点
- 静止检查点:
- 停止接受新的事务
- 等到所有当前活跃事务提交或中止,并在日志中写入了COMMIT或ABORT记录
- 将日志刷新到磁盘
- 写入日志记录
,并再次刷新日志
- 非静止检查点
- 在进行检查点时不必关闭系统,允许新事务进入
redo日志
Undo日志的一个问题
将事务改变的所有数据写到磁盘前不能提交该事务
redo日志
更新记录的格式
redo日志的规则
- 写磁盘的顺序为:
- 更新记录
- COMMIT日志
- OUTPUT(X)
- 更新记录
- 使用redo日志的恢复
恢复管理器的工作:
- 确定已提交的事务。
- 从首部开始扫描日志。对遇到的每一
- 如果T是未提交的事务,则什么也不做。
- 如果T是提交的事务,则为数据库元素X写入值v。
- 对每个未完成的事务T,在日志中写入一个
记录并刷新日志。
下面是一个redo日志的例子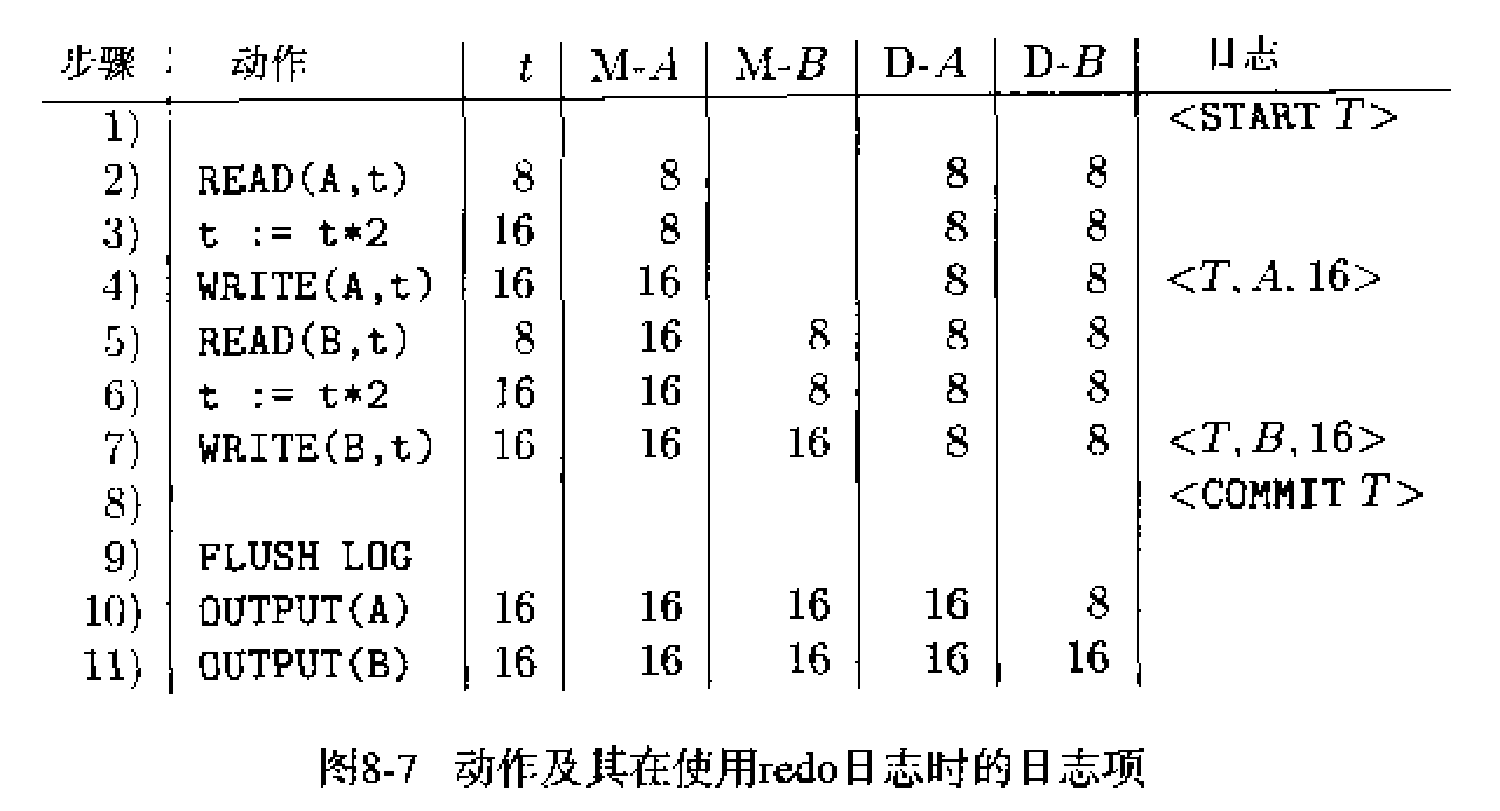
redo日志的检查点
- 不管检查点是静止的还是非静止的,在检查点的开始和结束之间我们必须采取的一个关键动作是将已被提交事务修改但还未写到磁盘的所有数据库元素写到磁盘
- 另一方面,我们不需要等待活跃事务提交或中止就能完成检查点,因为它们无论如何都不允许在那个时候将它们的页写到磁盘

检查点恢复规则
- 找到最后一个
日志 - 对于在相应检查点插入时活跃的事务和插入检查点之后开始的事务,记录所有需要Redo的已提交事务
- 从需redo事务中最早开始的事务向后扫描,并Redo所有需要提交的事务
- 对未提交的事务插入

undo日志vs.redo日志
Undo日志与Redo日志的主要区别
当数据库元素被修改时日志中保存旧值还是新值
- Undo日志要求数据在事务结束后立即写到磁盘,可能增加需要进行的磁盘I/O数
- Redo日志要求我们在事务提交和日志记录刷新以前将所有修改过的块保留在缓冲区中,可能增加事务需要的平均缓冲区数
undo/redo日志
undo/redo日志结合了两种日志的优点
代价:在日志中维护更多信息
undo/redo日志规则
- 在事务T所更新磁盘上的数据库元素X之前,相应日志记录
- 注意:此处没有任何对commit日志记录的要求,Undo/Redo日志仅需要满足Undo 和Redo日志共同的限制
undo/redo日志恢复过程
- 从后往前扫描日志,构造undo-list和redo-list
- 对每个形如
的记录,将Ti 加入redo-list - 对每个形如
的记录,如果Ti不属于redo-list,则将Ti加入undo-list
- 对每个形如
- 由后至前扫描日志,对undo-list中的每个事务 Ti的每一个日志记录执行undo操作
- 在具体实现中本步骤可以和第一步一起进行
- 由前至后重新扫描日志,并且对redo-list中每个事务Ti的每一个日志记录执行redo操作
- 对每个未完成的事务在日志Ti末尾加入
, Flush log 并将数据库置为正常状态
- 对每个未完成的事务在日志Ti末尾加入
undo/redo日志的检查点
- 写入日志记录
,其中,T1, …, Tk是所有的活跃事务, 并刷新日志 - 将所有脏缓冲区写到磁盘,脏缓冲区即包含一个或多个修改过的数据库元素的缓冲区
- 注意:该过程并不将检查点开始和结束之间修改的数据写入磁盘
- 写入日志记录
并刷新日志
防备介质故障
- 当主存数据丢失时,日志可以保证磁盘上的数据不会丢失。
- 然而,当一个或多个磁盘丢失时,如果下列条件成立,可以通过日志重建数据库:
- 日志所在的磁盘不同于存放数据的磁盘
- 日志在检查点以后不会被丢弃,并且
- 日志是redo或undo/redo类型,因而新值被存储在日志当中
- 然而,实际中,日志的增长远比数据库快,所以,永远保存日志是不现实的
防备介质故障的措施
备份:当介质故障发生时,数据库可以恢复到备份那一时刻的状态
- 要前进到一个更近的状态,可以使用日志
- 具体方式
- 完全转储
- 增量转储
日志恢复